Problemas de classificação
O método de classificação tem como objetivo classificar um conjunto de dados entre estados ou tipos distintos. Um bom exemplo de um problema de classificação é quando queremos prever se um tumor é maligno ou benigno baseando-se apenas no tamanho do tumor.
Podemos usar o algoritmo de regressão linear para classificar uma base de dados em dois diferentes grupos, como por exemplo, para valores de \( h(x) > 0.5 \) e para valores \( h(x) \leq 0.5 \). Contudo, essa forma de implementação não funciona muito bem, pois os problemas de classificação, geralmente, não cabem em problemas de regressão linear.
De outra forma, gostaríamos de classificar nossa base de dados em saídas discretas. Como base, iremos nos focar nos problemas de classificação binários (binary classification problems), os quais os valores de \( y \) podem assumir apenas dois valores: zero ou um, em outras palavras \( y \in 0,1 \).
Podemos representar um problema de classificação através da imagem a seguir na Figura 9
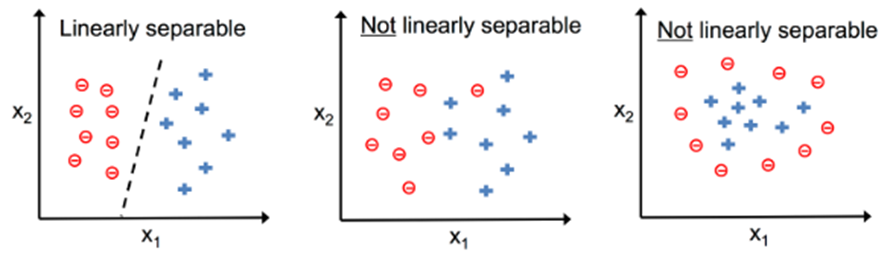
Figura 9: Representação de um problema de classificação
Podemos perceber que na Figura 9 temos dois tipos de classificações: linearmente separáveis e não linearmente separáveis. Nesta seção iremos discutir os problemas binários linearmente separáveis sem necessidade de regularização da função.