Multi-head attention e geração da saída
Na seção anterior, definimos apenas uma das cabeças do mecanismo de multi-head attention. Agora, precisamos gerar a saída para as outras cabeças.
Essas outras cabeças são necessárias para focar em outros elementos da sentença, ou, no caso do exemplo, em outros elementos da imagem.
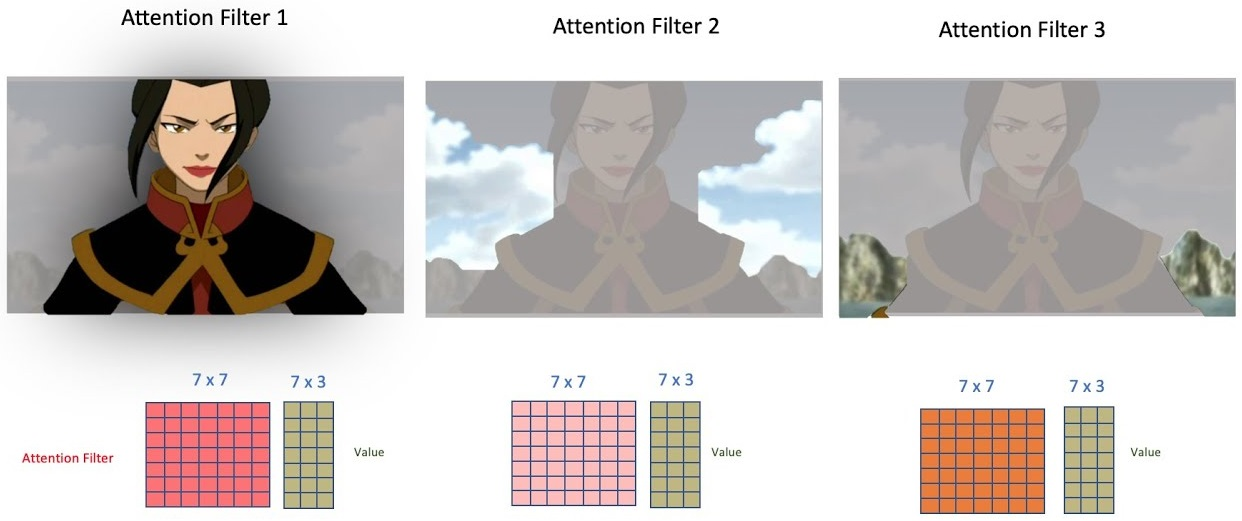
Figura 85: Exemplificação do mecanismo de multi-head attention com os filtros aplicados em diferentes na mesma imagem, porém, focando em diferentes elementos.
Definimos o mecanismo de multi-head attention da seguinte forma:
\[ \large{} MultiHead (Q,K,V) = Concat(head _1 , \dots , head _h) W ^O \]
onde \( W ^O \) são os pesos da linear layer de saída e \( head _i = Attention (QW _i ^Q , KW _i ^K , VW _i ^V) \).
No final da camada de multi-head attention concatenamos essas três matrizes geradas com o filtro aplicado. Depois, através de conecções residuais (residual skip connections [8]), normalizamos a matriz de saída através do método de layer normalization (LN) [3] e geramos o saída através de uma linear layer. Na Figura 86 a seguir, podemos visualizar a estrutura de um encoder de um transformer.
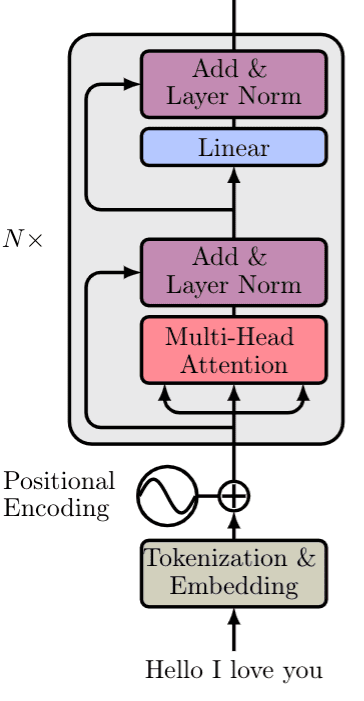
Figura 86: Representação da estrutura de um encoder de um transformer.
Por fim, para gerar o resultado da saída do modelo, devemos passar esses dados gerados na camada de encoding para a camada de decoding.